



Antwort Wie funktioniert HDFS? Weitere Antworten – Wie funktioniert Hadoop

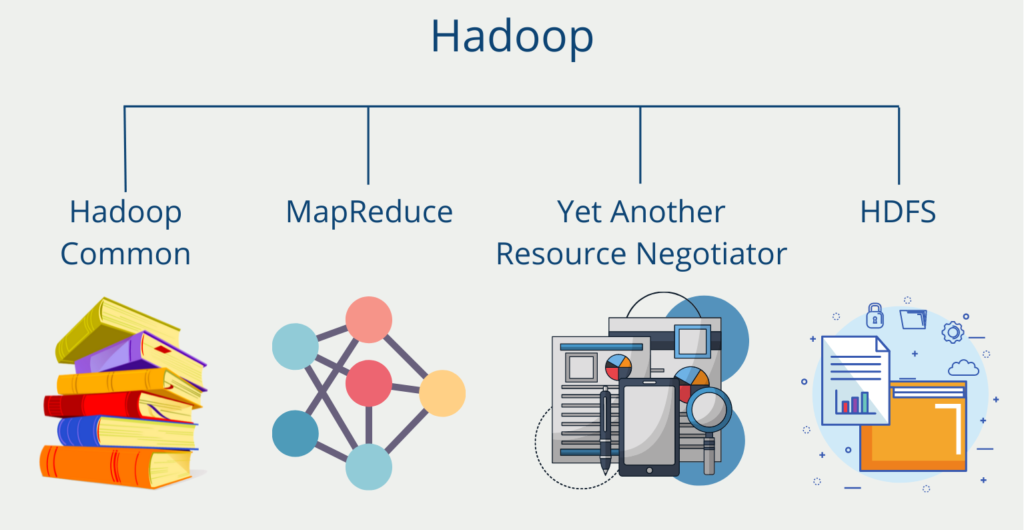
Das funktioniert nach einem recht einfachen Prinzip: Hadoop teilt enorme Datenmengen in kleine Päckchen auf, die auf mehreren Clusterknoten parallel verarbeitet und später wieder zusammengeführt werden. Google nutzt MapReduce, um die enormen Datenmengen der Suchmaschine zu verarbeiten.HDFS (Hadoop Distributed File System) ist das primäre Speichersystem, das von Hadoop-Anwendungen verwendet wird. Dieses Open-Source-Framework zeichnet sich durch schnelle Übertragungen von Daten zwischen Knoten aus.Hadoop wird am häufigsten mit Data Lakes in Verbindung gebracht. Ein Hadoop-Cluster aus verteilten Servern löst das Problem, große Datenmengen zu speichern. Das Herzstück von Hadoop ist seine Speicherebene namens HDFS (Hadoop Distributed File System), die Daten über mehrere Server hinweg speichert und repliziert.
Wie wird Big Data gesammelt : Big Data Tools und Methoden
Große Datenmengen bringen Komplexität mit sich und daher ist es nicht verwunderlich, dass herkömmliche Datenbanken für Big Data nicht mehr ausreichen. Vielmehr kommen erweiterte Analytics-Techniken wie Data Mining, Text Mining, Process Mining und Machine Learning zum Einsatz.
Was ist ein Cluster in Hadoop
Hadoop-Cluster replizieren einen Datensatz im gesamten verteilten Dateisystem und sind so widerstandsfähig gegenüber Datenverlust und Ausfällen. Hadoop-Cluster ermöglichen die Integration und Nutzung von Daten aus mehreren verschiedenen Quellsystemen und Datenformaten.
Was ist Hadoop Big Data : Apache Hadoop ist eine verteilte Big Data Plattform, die von Google basierend auf dem Map-Reduce Algorithmus entwickelt wurde, um rechenintensive Prozesse bis zu mehreren Petabytes zu erledigen. Hadoop ist eines der ersten Open Source Big Data Systeme, welches entwickelt wurde und gilt als Initiator der Big Data Ära.
Ein Data Lake ist ein Speicher, in dem große Mengen strukturierter, unstrukturierter oder halbstrukturierter Daten gespeichert werden können. Dort können alle Arten von Daten in ihrem nativen Format gespeichert werden. Wie in einem echten See fließen die Daten aus verschiedenen Quellen in Echtzeit zusammen.
Ein Data Lake ist ein großer Pool mit Rohdaten, für die noch keine Verwendung festgelegt wurde. Bei einem Data Warehouse dagegen handelt es sich um ein Repository für strukturierte, gefilterte Daten, die bereits für einen bestimmten Zweck verarbeitet sind.
Wie funktioniert das Datensammeln
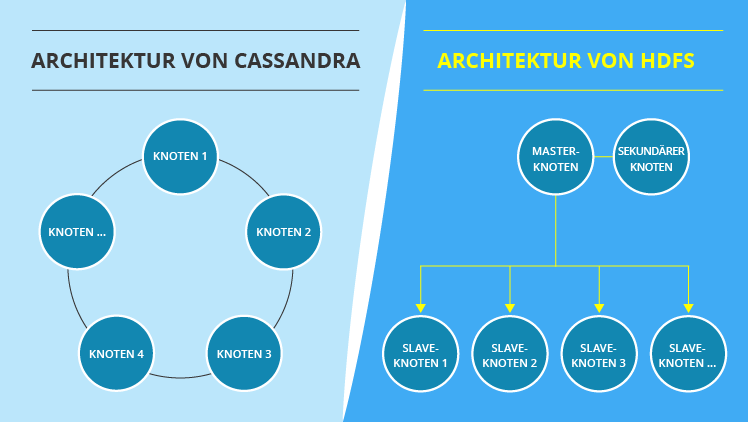
Der Begriff beschreibt die Möglichkeit, massenweise Daten in Echtzeit zu sammeln, verschiedene Datensets zu verbinden, zu analysieren und darin Muster zu erkennen. Häufig werden diese Muster genutzt, um Rückschlüsse auf das Verhalten oder die Einstellungen von Bürgerinnen und Bürgern zu ziehen, doch mehr dazu später.Forschungseinrichtungen oder Unternehmen speichern große Datenmengen oft auf Magnetbändern. Für den Eigengebrauch sind externe Festplatten oder USB-Sticks für mittlere bis große Datenmengen (im hohen GB- oder im TB-Bereich) im Handel problemlos erhältlich.Ein Cluster bezieht sich auf einen Rechnerverbund, in dem Server im Cluster zu einer effizienten Einheit kombiniert werden. Solche Verbindungen geschehen über ein Netzwerk, bei dem diese Server, oftmals von hoher Leistung, durch Switches und Lastverteiler verknüpft sind.

Clustering ist eine Methode der Datenaufbereitung, die im Marketing eingesetzt wird, um ähnliche Kundengruppen zu identifizieren. Dabei werden die Daten nach bestimmten Kriterien wie demografischen Merkmalen, Kaufverhalten oder Interessen segmentiert und Gruppen mit ähnlichen Eigenschaften gebildet.
Wie kann man Big Data nutzen : Mithilfe von Big-Data-Analysen lassen sich Unternehmensprozesse innovieren. Sie werden eingesetzt, um die Interaktionen, Muster und Anomalien innerhalb einer Branche und eines Markts präzise zu analysieren – und so neue, kreative Produkte und Tools auf den Markt zu bringen.
Ist ein Data Warehouse eine Datenbank : Nein. Ein Data Warehouse ist eine zentrale Datenquelle für ein Unternehmen, wo Daten aus operativen Systemen (wie ERP & CRM), Datenbanken und auch externen Systemen zusammenlaufen. Hier werden neben den aktuellen Daten auch historischen Daten zusammen an einem Ort gespeichert.
Wie werden Daten im Internet gesammelt
Kennen Sie das Jeder, der im Internet surft, hinterlässt Spuren: welche Seiten wann besucht, was dort geklickt und welches Gerät dafür benutzt wurde. Solche Daten werden über sogenannte Cookies gesammelt. Cookies sind Textdateien, die Webseiten bei einem Besuch automatisch auf Ihrem Rechner abspeichern.
Die wichtigsten Datenquellen
- Profile in Sozialen Netzwerken.
- Besuchte Websites und Online-Shops.
- Digitale Kommunikation.
- Suchmaschinen.
- Unterwegs mit dem Smartphone.
- Apps.
- Bezahlen.
- Internet der Dinge (IoT).
Archivierung der Big Data
Zur Speicherung von Massendaten werden vor allem Offline-Storage-Systems wie Tape Libraries favorisiert. Das Speichervolumen lässt sich einfach durch weitere Datenträger erweitern und bietet deswegen eine dauerhafte und robuste Lösung zum speichern der Big Data.
Wie entsteht Big Data : Big Data entsteht in einer zunehmend digitalisierten Welt von allein. Tagtäglich werden neue Informationen generiert, was wiederum zu einer stetigen Zunahme der Datenmengen führt. Unter anderem stammen die Daten aus folgenden Quellen: Nutzung von Internetdiensten und Social Media.